Wie Deep-Learning das personalisierte Marketing optimieren kann

Einsatz von Deep-Learning im Marketing
Individuelle Produktempfehlungen sind bei den meisten Unternehmen bereits fester Bestandteil ihrer Personalisierungsstrategie. Etablierte Recommendation-Engines verwenden dabei in der Regel Click- und Transaktions- sowie strukturierte Content-Daten (z.B. Artikelstammdaten) zur Berechnung von Produktempfehlungen.
In diesem Blog-Beitrag berichtet unser Gastautor, Dr. Sebastian Moll, wie Personalisierung auch anhand von Produktbildern umgesetzt werden kann, um so einen Mehrwert mit Hilfe von bislang kaum genutzten Daten zu schaffen. Dieser Beitrag knüpft dabei an unser Seminar von der DMEXCO 2018 an, in dem wir das Thema „How to use deep learning and image data to increase sales with personalized recommendations“ in einem exklusiven Vortrag behandelt haben. Bilder und Eindrücke dieses Vortrags finden Sie am Ende des Beitrags.
Deep-Learning-Image-Recommender
„Ein Bild sagt mehr als 1000 Worte…“
Welche Informationen braucht man um präzise Empfehlungen zu ermitteln und Substitutionsartikel zu identifizieren? Dieses Beispiel zeigt welche Informationen eigentlich innerhalb des Shop-Systems zu den verschiedenen Artikeln verfügbar sind:
| Version 1
Der Kunde kaufte: | Version 2
Der Kunde kaufte: |
|
 |
| Wenig strukturierte Informationen
(Metadaten von Produkten) | Viele unstrukturierte Informationen
(Bilder von Produkten) |
Bilder sind eine reichhaltige Informationsquelle, da sie sehr verdichtete Informationen enthalten. Nicht nur über einzelne Objekte, sondern auch über den Kontext. Dabei können auf Bildern einzelne Objekte dargestellt sein (z.B. ein T-Shirt), aber auch Relationen zwischen Objekten (z.B. ein Outfit bestehend aus T-Shirt, Hose und Schuhen). Und in Zeiten von DSGVO und ePrivacy ebenfalls relevant: Bilder eigener Produkte unterliegen keiner Datenschutzrichtlinie.
Strukturiert und unstrukturiert
Zu einzelnen Artikeln liegen in der Regel Bilder und Metadaten vor. Diese werden in Content-Management-Systemen gespeichert und verwaltet und von dort aus Anwendungen zugeführt.
Bei der Auswertung von Data-Warehouse-Daten beschränkt man sich zurzeit auf Metadaten der Artikel bzw. Produkte, da diese strukturiert vorliegen. Die Produktattribute umfassen zum Beispiel Farben, Muster oder weitere Unterkategorien. Diese können sehr einfach in Analysen oder Abfragen integriert werden. Informationen aus Bildern liegen erst einmal unstrukturiert vor, man hat nur das Bild und muss die Informationen daraus strukturieren, d.h. zugänglich machen. Man hat also über Produkte in der Regel wenig strukturierte Informationen und viele unstrukturierte Informationen.
Wie bekomme ich Informationen aus den Bildern?
Informationen aus eigenen Bildern automatisiert zu extrahieren, war in der Vergangenheit eine große Herausforderung. Die Technologien, die das heute ermöglichen, haben sich in den vergangenen Jahren rapide weiterentwickelt und können mittlerweile in gängigen Analysetools integriert werden.
Die Rede ist von Deep-Learning-Modellen, mit deren Hilfe u.a. Informationen aus Bildern in numerische Daten transformiert werden können. Genauer gesagt findet eine Informationsverdichtung statt. Wenn man ein 1-Megapixel-Bild als Beispiel heranzieht, sind das 1000×1000 (Auflösung) x 3 (Farbkanäle), also 3 Millionen einzelne Datenpunkte. Diese sind so noch nicht hilfreich und die enthaltenen Informationen müssen verdichtet werden.
Im Bereich der Bilderkennung und -klassifikation nehmen sog. Convolutional-Neural-Networks eine Schlüsselrolle ein. Sie ermöglichen durch den Einsatz von Filtern, einer datengetriebenen Parametrisierung und einer hierarchischen Anordnung über viele Ebenen (deshalb „Deep“), eine Informationsverdichtung und die Identifikation komplexer Strukturen. Damit können Attribute wie Farbe, Formen und Muster erkannt werden. Diese Informationen werden genutzt, um Bilder hinsichtlich „Ähnlichkeit“ miteinander zu vergleichen, einzelne Objekte auf Bildern zu identifizieren bzw. zu lokalisieren sowie um automatisiert viele weitere Artikelattribute zu ermitteln (Automatisiertes Tagging).
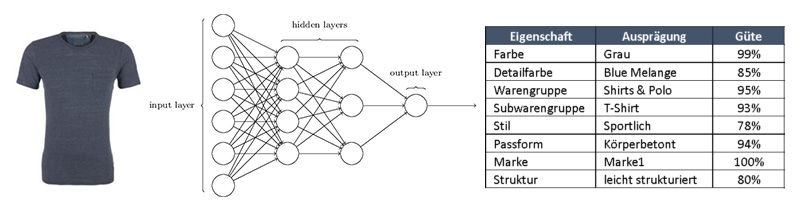
Ein konkreter Anwendungsfall im Marketingumfeld
„Ein Artikel ist nicht mehr verfügbar. Man kann seinen Kunden auf die Verfügbarkeit in 4 Wochen vertrösten oder …“
… einen alternativen Artikel anbieten! Am Besten gleich mehrere.
Es gibt gängige Varianten, das zu tun:
- Artikel anbieten, die mit dem nicht mehr verfügbaren Artikel häufig zusammen gekauft wurden (Klassischer Recommendation-Ansatz).
Diese Art der Produktempfehlung ist Bestandteil fast aller gängigen Recommendation Engines und daher leicht zu implementieren. Es können jedoch Vorschläge, die im konkreten Anwendungsfall als eher unpassend wahrgenommen werden, auftreten. Wenn ein Kunde bspw. ein Hemd sucht, dann möchte er ein Hemd oder zumindest ein Oberteil und nicht etwas, was häufig zusammen mit einem Hemd gekauft wurde. Mittels Business Regeln lässt sich das allerdings weiter einschränken (z.B. nur auf Oberteile). - Artikel anbieten, die dem nicht mehr verfügbaren Artikel optisch sehr ähnlich sind.
Bei dieser Möglichkeit ist der aus Sicht des Kunden der wohl passendste Ersatz zu erwarten.

Hohe Relevanz ohne großen manuellen Aufwand. Die Bilder werden mittels oben beschriebener Methoden verrechnet. Die Informationsverdichtung und Abbildung als numerische Information ermöglicht den Vergleich von Bildern hinsichtlich optischer Ähnlichkeit durch Computer. Es können also beispielsweise die Top-10 ähnlichsten Artikel pro Artikel als strukturierte Information berechnet, abgelegt und einer Anwendung zugesteuert werden.
Wie im obigen Beispiel gezeigt, gelingt es mit diesem Ansatz dem Webshop-Besucher höchst relevante Produktvorschläge zu unterbreiten. Und die Erfahrung aus etlichen Test bestätigt dies: Image Based Recommendations sind in der Lage für den Nutzer auf der Suche nach passenden Artikeln einen echten Mehrwert zu bieten und damit die Conversion Rate nachhaltig zu erhöhen.
Nachfolgend die Bilder des Seminars von Dr. Sebastian Moll und Alexander Kull auf der DMEXCO 2018. Gerne senden wir Ihnen bei Interesse auch die Unterlagen des Vortrags zu, schreiben Sie uns einfach eine E-Mail.





© Titelbild: metamorworks | www.fotolia.com
© Beispielbilder: www.google.com





